推理¶
通用推理方案(dlinfer)¶
dlinfer提供了一套将国产硬件接入大模型推理框架的解决方案。 对上承接大模型推理框架,对下在eager模式下调用各厂商的融合算子,在graph模式下调用厂商的图引擎。 在dlinfer中,我们根据主流大模型推理框架与主流硬件厂商的融合算子粒度,定义了大模型推理的融合算子接口。
这套融合算子接口主要功能:
将对接框架与对接厂商融合算子在适配工程中有效解耦;
同时支持算子模式和图模式;
图模式下的图获取更加精确匹配,提高最终端到端性能;
同时支持LLM推理和VLM推理。
目前,我们正在全力支持LMDeploy适配国产芯片,包括华为,沐曦,寒武纪等。
架构介绍¶
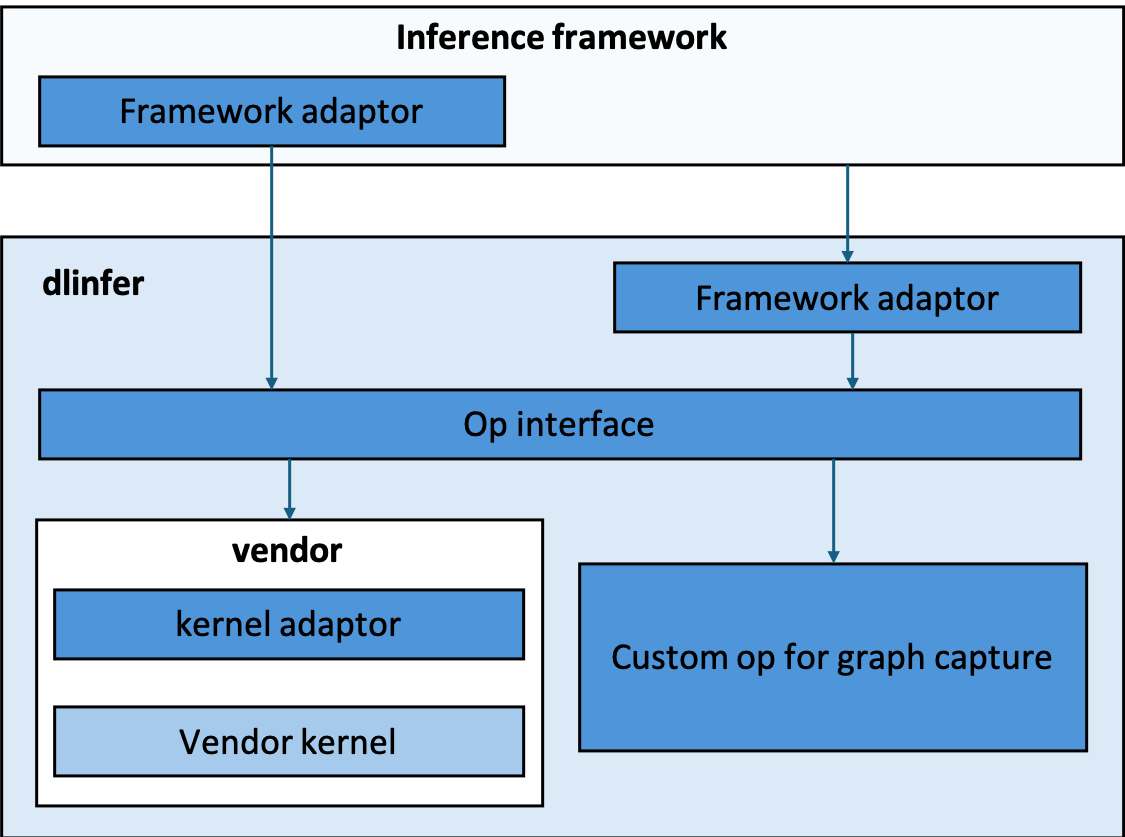
组件介绍¶
op interface: 大模型推理算子接口,对齐了主流推理框架以及各个厂商的融合算子粒度。
算子模式:在pytorch的eager模式下,我们将通过op interface向下分发到厂商kernel。由于各个厂商对于参数的数据排布有不同的偏好,所以在这里我们并不会规定数据排布,但是为了多硬件的统一适配,我们将会统一参数的维度信息。
图模式:在极致性能的驱动下,在一些硬件上的推理场景中需要依靠图模式。我们利用Pytorch2中的Dynamo编译路线,通过统一的大模型推理算子接口,获取较为粗粒度算子的计算图,并将计算图通过IR转换后提供给硬件厂商的图编译器。
framework adaptor: 将大模型推理算子接口加入推理框架中,并且对齐算子接口的参数。
kernel adaptor: 吸收了大模型推理算子接口参数和硬件厂商融合算子参数间的差异。
模型芯片适配列表¶
LMDeploy¶
| 模型系列/型号 | NV (全系列) |
华为 A2 |
沐曦 C500 |
平头哥 PPU 810 |
寒武纪 MLU370 |
|---|---|---|---|---|---|
| Llama系列 Llama3-8B Llama1-7B |
✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| InternLM系列 InternLM2.5-7B InternLM2.5-20B InternLM2-7B InternLM2-20B |
✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| Qwen系列 Qwen2-7B |
✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| Mixtral系列 Mixtral8x7B |
✔️ | ✔️ | ✔️ | ||
| InternVL系列 InternVL1-5 InternVL2-2B |
✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| CogVLM系列 CogVLM1 CogVLM2 |
✔️ | ✔️ | ✔️ | ||
| (*) DeepSeek系列 | ✔️(持续优化中) | ✔️(持续优化中) | ✔️(持续优化中) |
使用LMDeploy¶
只需要指定pytorch engine后端为ascend,不需要其他任何修改即可。详细可参考lmdeploy文档。
示例代码如下:
import lmdeploy
from lmdeploy import PytorchEngineConfig
if __name__ == "__main__":
pipe = lmdeploy.pipeline("/path_to_model",
backend_config = PytorchEngineConfig(tp=1,
cache_max_entry_count=0.4, device_type="ascend"))
question = ["Shanghai is", "Please introduce China", "How are you?"]
response = pipe(question, request_output_len=256, do_preprocess=False)
for idx, r in enumerate(response):
print(f"Q: {question[idx]}")
print(f"A: {r.text}")
print()